https://arxiv.org/abs/2406.17343 , CVPR 2025 (Accepted)
Q-DiT: Accurate Post-Training Quantization for Diffusion Transformers
Recent advancements in diffusion models, particularly the architectural transformation from UNet-based models to Diffusion Transformers (DiTs), significantly improve the quality and scalability of image and video generation. However, despite their impressi
arxiv.org
Abstract
최근 diffusion 모델이 UNet기반의 구조에서 Transformer로 전환되며, 이미지나 영상의 품질이 향상되고 있음. (Sora AI, Stable Diffusion 3 등)
하지만, Transformer 기반 Diffusion Model은 높은 연산 비용으로 인해 실 활용에 제약이 존재함. 이러한 문제를 해결하기 위해 학습 없이 모델을 압축할 수 있는 Post-Training Quantization(PTQ) 기법이 주로 활용됨. 하지만, PTQ 기법은 대부분 UNet 구조에 최적화되었으며, 이를 Transformer 기반의 Diffusion Transformer(DiT)에 바로 적용하는 경우 성능저하가 매우 크게 일어난다는 한계가 존재함.
본 논문에서는 다음과 같음 DiT의 특성 때문에 quantization 성능이 좋지 않음을 지적함.
1) Input Channel 간 weight 및 activation의 큰 분산
2) Time step에 따른 activation 분포의 동적 변화
또한, 이 문제를 해결하기 위한 Q-DiT를 제안함.
Q-DiT는 레이어별로 최적의 group size를 선정하여 quantization하며, 각 time step마다 activation을 실시간으로 양자화함.
ImageNet 및 VBench 실험에서 Q-DiT는 W6A8(weight 6-bit, activation 8-bit) 환경에서 원본에 근접하는 성능을 유지하였으며, W4A8과 같이 더 극단적인 환경에서도 뛰어한 성능을 보임.
Introduction
Diffusion Transformer(DiT)의 등장으로 이미지 및 영상 생성 품질이 향상되었지만, 매우 높은 연산 비용으로 인해 실제 서비스 적용에 어려움이 존재함. 기존의 PTQ(Post-Training Quantization)는 학습 없이 양자화가 가능하다는 장점이 있으나, DiT에 바로 적용 시 성능 저하가 큼. 본 논문은 DiT 구조의 특징(채널 간 activation/weight 분산과 timestep별 activation 분산)을 반영하여 이를 해결하는 Q-DiT를 제안함.
Contributions
1) DiT에 최적화된 PTQ 방안을 제안
- 입력채널의 넓은 분산 문제를 해결하기 위해 fine-grained group quantization 기법 적용
- timestep과 샘플마다 변하는 actviation 분포를 동적으로 quantization
2) 고정된 group size를 기반으로 한 quantization은 비효율적이라는 점을 규명함.
- 이를 개선하기 위해, FID/FVD 점수를 활용한 group size 할당 방식을 제안
3) 더 극단적인 양자화 환경(압축률 높은 환경) 실험에서 우수한 성능을 입증
Related Work
Model Quantization
모델 양자화는 QAT(Quantization-Aware Training)과 PTQ(Post-Training Quantization)으로 나뉨. PTQ는 추가적인 학습 없이 작인 calibration set만으로 양자화가 가능함.
Transformer Quantization
Transformer을 대상으로 한 양자화는 ViT와 LLM에 초점을 두어 연구됨.
Diffusion Quantization
Diffusion 양자화는 기존의 UNet 기반 구조에 대해 다뤘으며, DiT(Diffusion Transformer)에 대한 양자화 연구는 많이 진행되지 않음.
Observation
Observation 1
DiT는 입력 채널 간 weight 및 activation 분산이 매우 큼.

Figure 2의 a를 보면 output channel인 y축에 비해 input channel인 x축의 값들이 일정하게 큰 것을 확인할 수 있음. 또한, (b)에서도 channel 축을 기준으로 값이 매우 큰 것을 확인할 수 있음. 이와 같은 결과를 통해 DiT는 입력 채널 간 weight 및 activation 분산이 매우 크다는 사실을 분석 가능함.
Observation 2
DiT는 Time step에 따라 activation 분포가 크게 달라지기 때문에 정적인 quantization parameter는 전체 time step에 일반화가 불가능함.


Figure 3과 4에서는 denoising 과정에서 time step에 따라 activation의 분포와 표준편차가 매우 다양하게 나타남을 확인할 수 있음. 또한 sample에 따라서도 다양한 분포가 생길수 있음을 확인할 수 있음.
Method

1) Automatic Quantization Granularity Allocation
채널 간 분산 문제 해결을 위해 group quantization을 도입함. 하지만, group size를 줄여서 quantization하는 방안은 항상 좋은 것은 아니며, 비단조성 (non-monotonicity, 일반화 문제) 존재함. 따라서, 이를 해결하기 위해 FID/FVD 척도를 통해 layer 별로 optimal한 group size를 탐색함.


Image Generation에서는 FID(Frechet Inception Distance)를 활용하며, R은 실제 샘플, G는 quantized model로부터 만든 샘플을 의미함. g는 layer에따른 group size configuration임.
Video Generation에서는 FVD(Frechet Video Distance) 평가지표를 활용함.
상세한 알고리즘은 다음과 같음.

1) 랜덤 초기화를 통해 여러개의 group size 조합(configuration)을 각 레이어 별로 만듦. 이를 Population P라고 함.
2) 여러번의 iteration 중 각 iteration마다의 각 group size에 대해 (for문 2개) 양자화된 모델을 생성함. 그 후, 모델이 생성한 이미지나 영상에 대해 위 수식을 기반으로 점수를 계산함. 계산된 결과를 바탕으로 가장 성능 좋은 K개의 조합만 골라 TopK 후보 세트에 저장
3) Crossover라는 과정을 통해 TopK안의 상위 조합들을 섞어서 새 조합을 생성 (부모 유전자 섞는 개념과 비슷). 연산량이 기준 이내이면 P에 추가
4) Mutation이라는 과정을 통해 TopK안의 상위 조합을 일부 랜덤하게 변형함. 이것도 연산량 기준 이내이면 P에 추가함.
5) 3번과 4번 과정을 통해 새로운 세대의 population을 생성하며, 모든 반복이 끝나면 최고 성능을 보이는 조합을 $g^{best}$로 선택함.
2) Automatic Quantization Granularity Allocation
Time step과 sample에 따라 activation 분포가 달라지므로, 실행 시점에(min-max 기반으로) sample마다 동적으로 activation을 양자화하는 과정을 거침.
Experiments
이미지 생성에서는 DiT-XL/2를 모델로 사용하며,256x256, 512x512 크기의 ImageNet을 활용함.
영상 생성에서는 STDiT3모델에서 VBench를 사용함.
Quantization 환경에서는 W4A8 및 W6A8 환경에서 성능을 평가함.
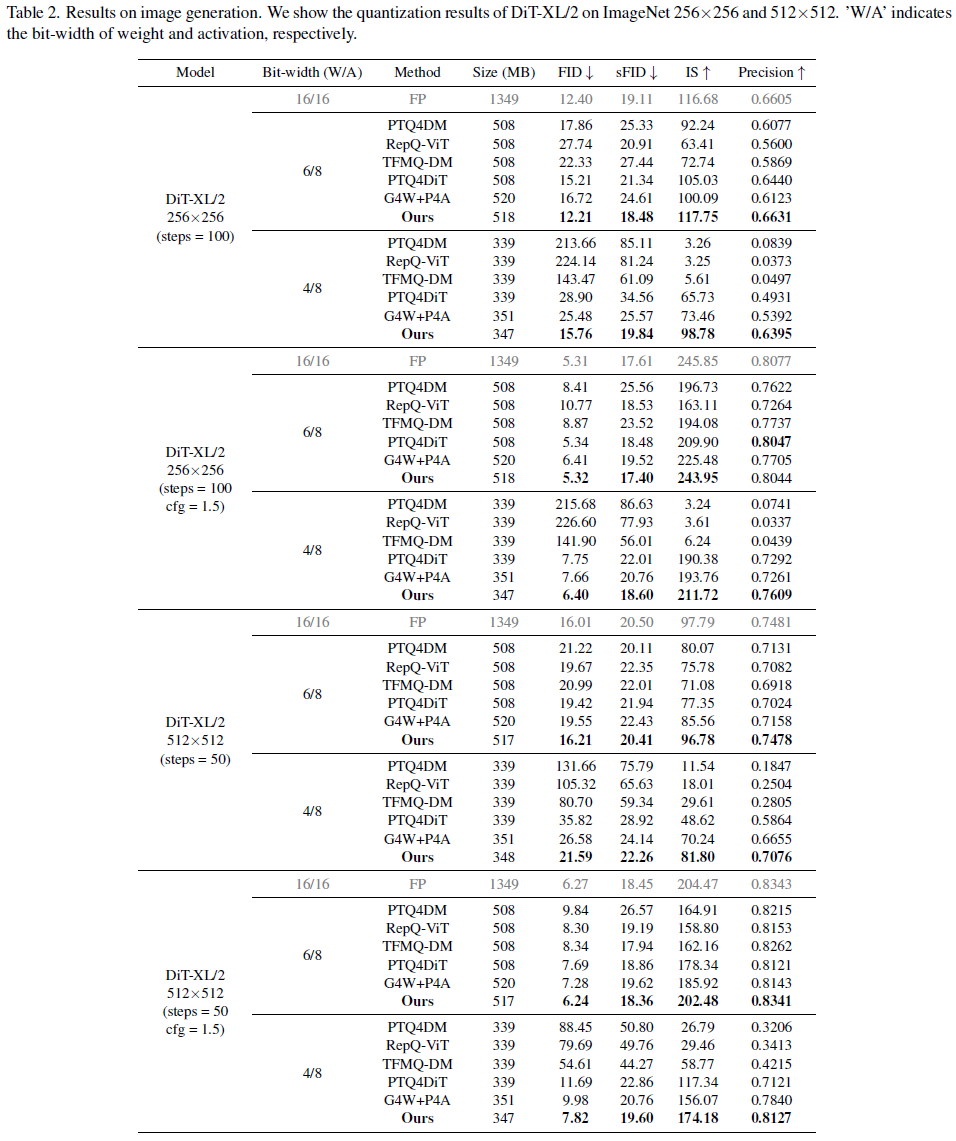

Q-DiT는 다른 SOTA 방법들과 비교했을 때 이미지 생성과 비디오 생성 Task 모두 월등한 성능을 보임.
Ablation study



Table 4를 보면, RTN(round to nearest) → group quantization → dynamic activation → group size search(제안방식) 순으로 성능이 점진적으로 향상됨.
Table 5는 time step + sample step을 모두 고려했을 때 가장 좋게 dynamic activation quantzation이 가능함을 보임.
Table 6에서는, 논문에서 제안한 group size search 방식이 다른 방식들에 비해 좋은 성능을 보임을 확인함.
Conclusion
Q-DiT는 DiT 모델의 양자화를 위한 새로운 PTQ 방법이며, group quantization과 동적 activation quantization을 통해 고성능을 유지함. 이러한 두 가지 설계는 개별적으로도 효과적이지만, 통합적으로 사용할 때 성능을 더욱 극대화할 수 있음.
실제로, ImageNet 256×256 데이터셋에서 W4A8로 양자화했을 때, 기존 full-precision 모델 대비 FID 손실이 1.09 증가에 불과할 정도로 성능 저하가 거의 없는 near-lossless quantization을 달성함.
한계점으로는 최적의 group-size를 찾는 과정이 계산비용이 매우 크고, 시간이 오래 걸림. 따라서, 향후 연구에서는 이 과정의 효율을 개선하는 연구를 할 예정이라고 밝힘.
Review
Strong Points
1) 기존 연구들은 Transformer 기반 Diffusion 모델에 대해 채널에 대한 분산이나 time step 별 분포변화에 대해 고려하지 않았지만, 본 논문은 이를 처음으로 분석하여, DiT에 특화된 PTQ 방안을 제안함.
2) W8A8의 환경까지만 실험하였던 기존 연구들과 달리 더 극한의 압축환경(W6A8)에서도 우수한 성능을 처음을 보임.
Weak Points
1) 논문에서 언급한 것처럼 group size 탐색을 위한 계산적 비용이 너무 크다고 생각함.
특히, FID / FVD를 뽑기 위해서는 각 group size 조합마다 모델 quantize → 샘플 생성 → FID/FVD 계산과정을 거치는데 매우 비효율적임.
2) Dynamic Activation quantization 파트에서 논문은 "prior operator에 통합되어 overhead가 적다"라고 말하고 있지만, 정량적인 분석이 없음.
3) Activation Quantization 측면에서 이 논문은 오로지 하나의 샘플만을 통해 zero-point와 scaling factor를 결정하는데, 이 부분으로 on-the-fly (실시간) quantization이 가능하다고 함. 하지만 하나의 샘플을 통한 계산은 추론 시마다 계산이 필요한데, on-the-fly라고 주장하기 위한 실험적 분석이 미흡하다고 생각함.



