https://arxiv.org/abs/2311.06322 , ECCV 2024
Post-training Quantization for Text-to-Image Diffusion Models with Progressive Calibration and Activation Relaxing
High computational overhead is a troublesome problem for diffusion models. Recent studies have leveraged post-training quantization (PTQ) to compress diffusion models. However, most of them only focus on unconditional models, leaving the quantization of wi
arxiv.org
Abstract
Diffusion 모델의 높은 계산량을 개선하기 위해 기존 연구들은 Post-Training Quantization(PTQ) 방식을 통해 양자화를 진행함. 하지만, 대부분의 방식들은 모델에 중점을 두며, Pre-trained Text-Image 모델 (e.g., Stable Diffusion)에 관한 양자화 연구는 거의 진행되지 않음. 본 논문에서는 Text-Image Diffusion모델을 양자화 하기위한 PCR(Progressive Calibration and Relaxing) 방안을 제안함. 또한, 기존에 활용되던 성능지표는 Text-Image Diffusion모델에 적절하지 않다는 문제를 제기하며, 이를 해결하기 위해 QDiffBench라는 성능지표를 제안함. 이를 통해 양자화된 모델의 일반화 성능까지 고려할 수 있음.
본 논문의 방식은 Stable Diffusion과 Stable Diffusion XL에서 우수한 성능을 보이며, Stable Diffusion XL에 대해 최초로 양자화를 진행하였음.
Introduction
최근 diffusion model은 text-to-image generation에 뛰어난 성능을 보이지만, 과도한 계산량(computational cost)이 한계로 지적됨. 그 원인은 아래와 같음
1) 여러단계 반복하는 denoising 과정
2) 거대한 네트워크 구조 (Foundation model의 구조 자체가 매우 큼)
본 논문에서는 2번째 문제에 중점을 두어 모델 크기 자체를 줄이는 방안을 제안함.
또한, 본 논문에서는 기존 연구의 문제점들을 다음과 같이 준석함
1) step 간 누적되는 quantzation error를 고려하지 않음
2) 기존 평가지표인 FID는 COCO데이터셋에 기반하여 계산되지만, 이는 평가데이터와 생성 이미지간의 distribution gap을 무시함
3) 학습에 쓰이지 않은 prompt에 대한 generation 성능이 고려되지 않음
본 논문에서는 증명을 통해 denoising step의 quantization error누적이 최종 생성이미지에 직접 영향을 준다는 분석을 진행하였으며, image fidelity와 text-image matching이 timestep에 따라 다르다는 것을 실험적으로 관찰함.
추가적으로, 기존 성능지표 (FID to COCO)로는 열등한 모델이 더 좋은 점수를 받는 현상을 지적함.
논문의 Contribution은 다음과 같음.
1) 점직적인 calibration 및 activation relaxing을 수행하는 PCR방식을 제안함
2) Text-to-Image Model의 효과적인 평가를 위해 QDiffBench라는 새로운 평가방식을 제안함
3) Stable Diffusion 및 Stable Diffusion XL을 대상으로 한 Quantization (PTQ)에서 우수한 성능을 보임
4) Stable Diffusion XL과 같이 거대한 모델을 처음으로 양자화에 성공함
Related Work
Model Quantization
PTQ (Post-Training Quantization): 작은 양의 데이터를 통해 신속하게 quantized model을 calibration하는 방식. 모델을 직접적으로 training하거나 fine-tuning하는 QAT(Quantization-Aware Training)보다는 성능이 떨어지지만 데이터의 제한을 적게 받아 빠르고 간편하게 사용할 수 있음.
Mixed Precisio Quantization: d모델 내 서로 다른 layer나 block에 다양한 크기의 표현범위(bit-width)를 두어 양자화 하는 방식. 보다 중요한 부분에는 큰 표현범위(ex.10-bit)로 양자화하고 중요하지 않은 부분에는 작은 표현범위(ex.8-bit)로 양자화함.
Diffusion Model Quantization
PTQ4DM (Shang et al.)의 경우 training 과정에 중점을 두기보다 denoising sampling process에서 calibration data를 활용하는 방식을 활용함. 또한, 각 time step에서의 calibration data가 skw-normal distribution으로 생성되어야 함을 제안함.
Q-diffusion의 경우 각 timestep에서부터 calibration data를 수집하고, skip conection구조를 분리하여 quantization하는 방식을 제안함.
하지만, 기존의 모든 방식들은 각 sampling step에서 누적되는 quantization error를 고려하지 않음.
또한, text-to-image 생성모델에 대한 고려가 이루어지지 않음을 본 논문에서 지적함.
Method
Preliminaries for Diffusion Models

Forward 과정에서는 원본이미지에 noise를 추가하는 과정임. 여기서 $x_0$는 원본이미지이고, $x_t$는 noise가 추가된 이미지임. 여기서 $\alpha_t$와 $\sigma_t$를 통해 noise를 추가함.

Reverse 과정에서는 위와 같은 loss를 기반으로 진행됨. 여기서 $\alpha_t x_0 + \sigma_t \epsilon, t$는 noise를 추가한 이미지의 예측값이며, $\epsilon$은 noise vector를 의미함. 이 두 값을 $L_2 norm$ 기반으로 하여 학습을 진행할 수 있음.
Time-Accumulated Error Aware Progressive Calibration
기존연구들에서는 activation의 분포(distribution)들이 time-step마다 다양하게 달라지며, 이는 diffusion model을 quantizing하기 어렵게 만드는 요인임을 분석하였음.
이러한 한계를 개선하기 위해 몇몇의 연구들은 시간적인 정보를 고려한 quantization (i.e., time-step마다 activation을 구분하여 quantization) 방식을 제안하였고, 본 논문에서도 이러한 방식을 기반으로 함.
모든 기존 연구들은 시간적인 정보를 고려한 quantization을 진행하긴 하지만, 누적되는 quantization error에 대해서는 고려하지 않음. 따라서 기존의 접근방식은 sub-optimal한 방식이며, 아래 figure와 같이 누적되는 quantization error에 대해 확인할 수 있음.
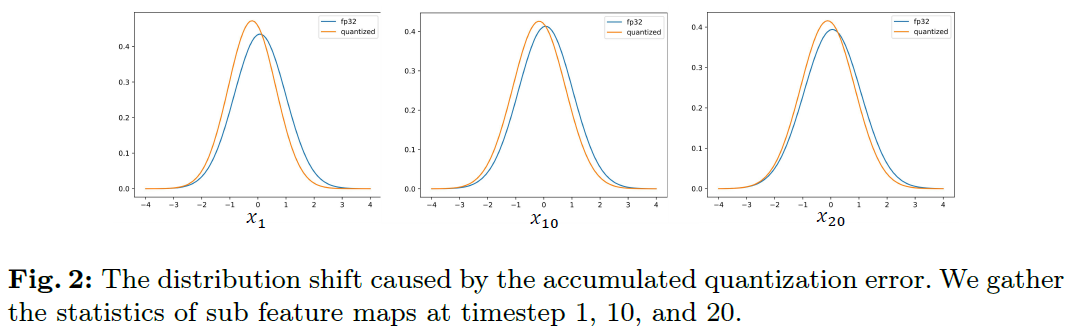
따라서, 다음과 같이 이전 step에 대해 모두 quantization을 진행하는 방안을 본 논문에서 제안함.

위와 같이 quantization을 이전 time-step까지 모두 진행하게 된다면 누적되는 quantization error를 줄일 수 있음.
Time-wise Activation Relaxing
본 논문의 저자들은 "text-image matching"과 "image fidelity"를 새롭게 정의함.
text-image matching은 이미지와 텍스트 프롬프트 간 의미론적 (semantic) 매칭을 의미하며, 고수준 정보를 의미함.image fidelity는 distortion과 noise와 같이 low-level의 loss를 의미함.

위 Figure는 time-step에 따른 activation quantization이 이미지 생성 품질에 미치는 영향을 보여줌.
분석결과, 초기단계에 해당하는 (b)에서는 text-image matching(고수준 정보)가 민감한 요소이며, 후기단계로 진행할수록 (d~e) image fidelity(저수준 정보)가 민감한 요소임.
이러한 분석을 기반으로, 가장 민감한 time-step 구간만 선택적으로 high bit quantization을 할당하며, 나머지 time-step에서는 low bit quantization을 유지해 연산 효율을 유지함.
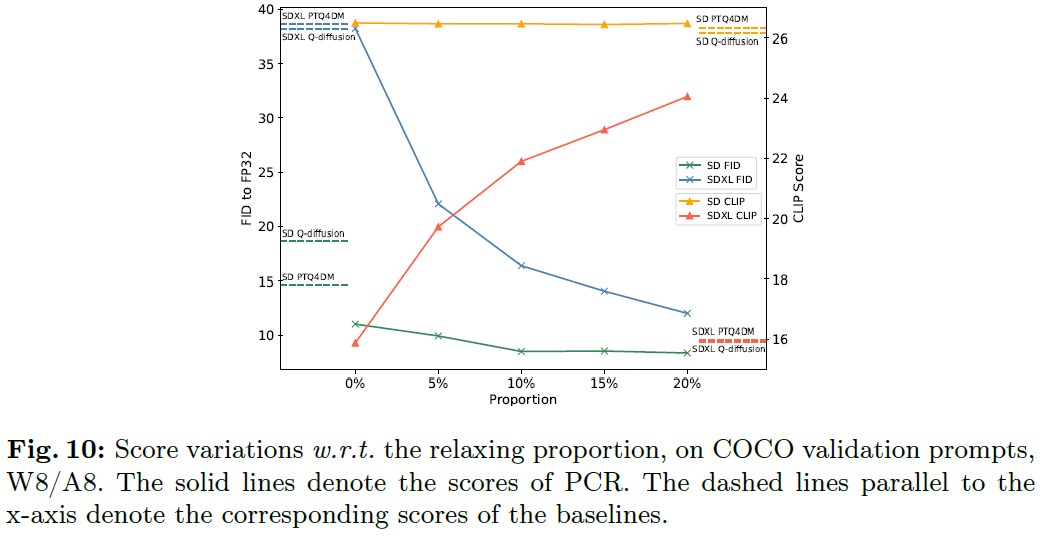
논문의 저자들은 전체 time-step 중 m개만 high bit로 설정하며, 이를 relaxation 비율로 정의함.
relaxation비율은 $\tau = m/T$로 정의하며, 이 비율은 20% 이하로 설정하는게 적절함을 제안함.
QDiffBench

실험은 COCO dataset으로 진행하였으며, 위 Figure와 같이 원본 COCO image와 quantized diffusion모델이 생성한 이미지를 비교하는 것 대신, Full-precision(원본 diffusion model)에서 생성한 이미지와 quantized diffusion모델이 생성한 이미지를 비교하는 FID to FP32 평가지표를 새롭게 도입함.
Experiments

위 Figure와 같이 새로운 평가지표와 CLIP score를 통해 time-step 간 image fidelity를 평가하였으며, text-image 매칭이 잘되는 단계와 잘 되지 않은 단계가 있음을 확인하였음.

위 Figure와 같이 본 논문의 방식의 8bit quantization은 FP Image와 거의 동일한 이미지를 생성하지만, 타 모델의 8bit quantization에서는 이미지 매칭이 좋지 않고, prompt와 맞지 않는 이미지를 생성함.





위 Table과 Figure들은 $\tau$가 0.2일때의 정성적, 정량적 결과를 나타내며, 다양한 지표에서 제안방식이 우수한 생성성능을 보임.
Ablation Studies는 아래와 같음.

Conclusion
본 논문은 Text-to-Image Diffusion 모델의 양자화에서 1) 방법론 2) 벤치마크 측면에서 발전시키는 것을 목표로 함. 저자들은 새로운 quantization 방식인 PCR을 제안하며, 효과적인 벤치마크인 QDiffBench를 제안함.
Review
Strong Points
본 논문은 Text-to-Image Diffusion 모델의 PTQ 기반 양자화에서 새로운 방식(PCR)과 새로운 벤치마크(QDiffBench)를 제안하며, 실험적인 검증도 적절히 진행함.
1) 기존 연구에서 time-step마다 quantization error가 누적되는 현상을 적절히 분석
2) 기존의 FID가 Quantized Diffusion모델의 image fidelity를 적절히 반영하지 못하는 문제를 적절히 제기
3) 이미지 생성성능에 대해 실험적으로 철저한 검증
Weak Points
1) Quantization error가 누적되는 현상에 대한 실험은 distribution에 대한 실험만 존재하며, 상세한 실험은 진행되지 않음
2) 민감한 time-step에 high bit를 적용하는 전략은 실험적(경험적)으로 설계되었으며, 이론적인 근거가 부족함.
(ex. 왜 10-bit로 설정하였는지, high bit를 설정하는 비율을 왜 20%로 설정하였는지 설명 부재)
3) Mixed-precision quantization의 경우 bit 설정조건에 따른 실행시간 (latency, throughput) 추가 실험이 필요함.
하지만, 논문에서는 negligible하다고 간략하게만 기술되어 있음.



