Liu, Zirui, et al. "Kivi: A tuning-free asymmetric 2bit quantization for kv cache." ICML 2024 (Poster)
https://icml.cc/virtual/2024/poster/34318
ICML Poster KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Abstract: Efficiently serving large language models (LLMs) requires batching many requests together to reduce the cost per request. Yet, the key-value (KV) cache, which stores attention keys and values to avoid re-computations, significantly increases memo
icml.cc
Abstract
LLM의 attention mechanism에서는 반복적인 계산을 줄이기 위해 KV cache(Key-Value Cache)를 활용함. 하지만 KV cache는 큰 batch-size와 긴 context를 처리할 때 메모리 사용량이 급격히 증가하여 bottle 현상을 일으킨다는 한계가 존재함.
이를 해결하기 위해 본 논문에서는 KV캐시의 메모리 요구사항을 줄이는 2-bit Quantization 알고리즘 (KIVI)를 제안함.
KIVI는 key cache는 channel별로, Value cache는 token별로 quantization을 진행하였으며, 이 방식은 메모리 사용량을 최대 2.6배 줄이면서 성능을 유지함. 또한, Llama-2, Falcon, Mistral 모델에서 최대 4배의 batch-size를 지원하며, 추론성능을 2.35배에서 3.47배까지 향상시킴.
Introduction
(Limitation 1)
KV cache는 LLM에서의 반복되는 연산을 방지하기 위해 key와 value를 저장함. 하지만 KV cache는 새로운 저장공간이 필요하며, 속도 관련 bottleneck이 존재함.
(Limitation 2)
또한, token이 생성될 때마다 KV cache를 load 해야는데, 이때 GPU의 SRAM은 유후상태가 되어 시간적인 낭비가 발생함.
(Research Background)
따라서, LLM의 성능은 유지하면서 KV cache의 size를 줄이는 것이 상당히 중요함.
이러한 한계를 개선하기 위한 기존의 방식은 크게 3가지로 구분할 수 있음.
(Previous Approach 1)
KV cache의 head 수를 절감하는 방식. (기존 모델에 training 과정을 거쳐야 함.)
(Previous Approach 2)
KV cache에서 중요하지 않은 token을 제거함으로써 size를 절감하는 방식.
(Previous Approach 1)
KV cache를 offloading하거나, 가상 메모리 확장하거나 paging기법을 활용 ( System 관점의 접근)
(Research Objective)
KV cache의 크기를 줄이는 가장 직관적이고 효과적인 방법은 Quantization을 활용하는 것이나, KV cache에 대한 quantization 연구는 미비하게 진행되었으며, 4-bit 환경에서만 진행되었음. 따라서, 본 논문에서는 분석을 통해 효과적인 KV cache의 quantization을 진행하며, 이 방식을 KIVI라고 제안함.
(Analysis & Approach)
기존의 KV cache quantization에서의 limitation을 상세하게 분석하였으며, 분석 결과는 다음과 같음.
1. Key cache의 경우 channel 별로 quantization하는 것이 효과적
2. Value cache의 경우 각각의 독립적인 token대로 quantization하는 것이 효과적

2번 value cache의 경우는 token대로 quantization을 진행하기 때문에 새롭게 token이 추가되어도 이것을 바로 추가해 저장할 수 있음.
하지만, 1번의 key cache의 경우 channel별로 quantization을 진행하기 때문에 streaming 환경에서 추가적인 저장이 직접적으로는 불가능함.
이를 해결하기 위해 본 논문에서는 key cache를 2 parts로 나누어 처리하는 방식을 제안함.
첫 번째 파트는 그룹화된 grouped key cache이며, 두 번째 파트는 그룹화가 되지 않은 residual key cache로 구성됨
그룹화된 첫번째 파트는 quantization이 이루어지며, 그룹화가 되지 않은 두 번째 파트는 quantization이 이루어지지 않음.
두 파트는 나중에 attention score를 계산할 때 matrix multiplication을 통해 합쳐짐.
(Contributions)
따라서, 본 논문의 주요 contributions는 2가지로 정리할 수 있음.
1. key cache는 channel, value cache는 token별로 quantization 하는 것이 효과적임을 제안함.
2. 위 분석을 바탕으로 KIVI라는 compression방식을 제안하며, 이는 LLM의 성능은 유지하면서 KV cache를 효과적으로 압축시킴. (plug-and-play 가능)
Related Work
KV cache는 2가지 과정을 거침. 논문에서는 이 과정도 자세히 설명되어 있으나, 분량 상 간단히 요약하였음.
1. Prefill Phase: 처음 input tensor가 들어올때 key, value tensor들을 cache에 저장하는 단계
2. Decoding Phase: KV cache를 업데이트하고, 최종적인 attention output을 계산하는 단계
Methodology
KV cache Quantization을 위한 Preliminary는 다음과 같이 정리함.
(Observation 1)
기존 KV cache quantization에서는 key와 value cache가 모두 token단위로 quantized됨. 이는 4-bit 환경에서는 성능을 유지할 수 있었음. 하지만, 2-bit 환경에서는 엄청난 성능하락이 일어남.
(Observation 2)
Value cache가 channel 단위로 quantized되면 엄청난 성능 하락이 일어남.
(Observation 3)
2-bit와 같은 low-bit환경에서 가장 적합한 접근은 key cache는 channel, value cache는 token단위로 quantization하는 것임.
아래 figure는 key, value cache에 대한 magnitude graph임.

이 figure를 통해 알 수 있는 사실은 아래와 같음.
Key cache: 특정 channel에서 매우 큰 magnitudes가 존재하며, 이것은 왜 key cache가 channel 별로 quantization되어야 하는지 보여주는 이유가 됨. key cache를 token별로 quantization하게 된다면, 범위가 큰 quantization error값이 모든 영역에 걸쳐 반영되고, 이는 quantization 성능을 하락시킴. 따라서, 각각의 channel에 대해 구분하여 quantization하는 것이 효과적임. 이는 실험을 통해서도 검증되었으며, 결과는 아래와 같음.

표의 첫번째 행은 reconstruction error에 해당하며, 두 번째 행은 relational attention score error에 해당함.
두 값 모두 channel로 quantization했을 때 더 낮은 error 값을 보여 channel 별 quantization이 더 효과적임을 보임.
Value cache: Key cache에 비해 특이점이 없음. (outlier pattern x). 따라서, token과 channel 기준의 quantization이 모두 활용될 수 있음. figure 2로는 왜 value cache가 token별로 quantization되어야 하는지 증명하지는 못함. 따라서, 저자들은 이를 증명하기 위해 value cache를 통해 attention output이 계산되는 수식을 추가적으로 보여줌.

이 수식에서 강조한 $X_{V}$는 다양한 token에 대해 summation연산이 수행되고 있음을 알 수 있음. 따라서, attention score를 산출하는 과정에서는 token이 중요한 영향을 미침을 알 수 있음.
따라서, value cache에서는 channel 별로 묶어서 quantizaiton하는 방식보다 token별로 quantization 하는 것이 더 효과적임을 직관적으로 알 수 있음. 해당 논리는 실험으로 추가적인 검증을 진행하였으며, 결과는 아래와 같음.

실험결과를 보면, token에서 강조한 relative error는 channel에 비해 15배나 작게 나온 것을 볼 수 있음.
(첫번째 행에 해당하는 reconstruction error는 별 차이가 없음, 조금 증가하였음)
앞서 분석한 Observation 1 ~ 3을 토대로 KV cache에 효과적인 quantization방식(KIVI)을 저자들은 제안하였으며, overall figure는 다음과 같음.
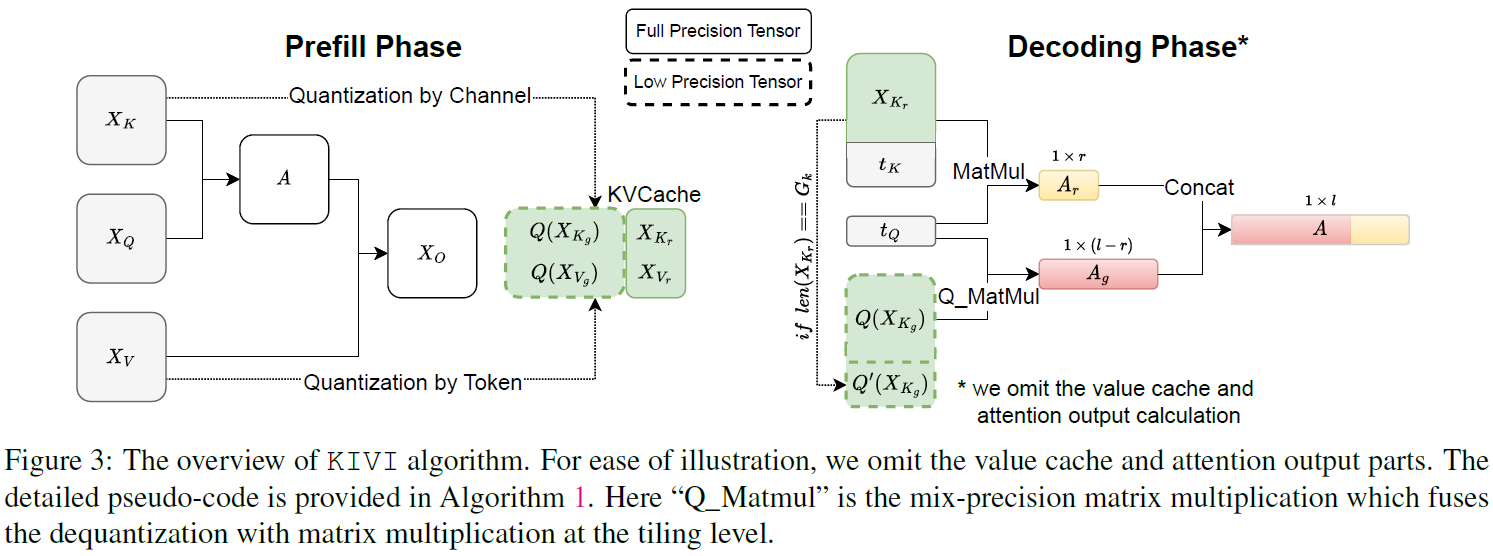
Prefill Phase: 모델이 입력 prompt를 받아들여, 해당 prompt에 대한 KV cache를 생성하는 단계임. 여기서 핵심과정은 $X_{K}$의 경우 channel을 기준으로, $X_{V}$는 token을 기준으로 quantization하는 과정임. 이때 key cache는 grouped key cache $Q(X_{K_{g}})$와 residual key cache $X_{K_{r}}$ 로 나뉨. 이전에 설명했듯, grouped cache만 quantization을 진행하게 되며, 그룹화 후 남은 residual key cache는 quantization을 진행하지 않음.
Decoding Phase: prompt와 cache를 기반으로 key cache를 업데이트하고, matrix multiplication이 이루어지는 단계임. 여기서 residual key cache가 계속 쌓여서 하나의 그룹만큼 쌓이면 $Q'(X_{K_{g}})$와 같이 quantization을 진행함. 그 후. residual key cache는 0으로 reset 함.

수식 첫 번째 행의 $A_{g}$의 경우 grouped key cache와 query에 대한 matrix-multiplication과정이며, 두 번째 행인 $X_{K_{r}}$은 기존의 residual key cache에 새로운 key token을 추가하는 과정임. 세 번째 행인 $A_{r}$은 residual key cache와 query를 matrix multiplication하는 과정이며, 최종적인 attention score $A$는 기존에 구했던 $A_{g}$와 $A_{r}$을 합치는 과정임.
value key의 과정도 위와 동일하게 두 개의 파트로 나누어 관리하는데, value key에서는 queue 자료구조를 통해 새롭게 들어오는 value cache를 관리함. 여기서 가장 오래된 queue가 pop 되어 제거됨.
Residual cache에 저장되는 token 개수는 최대 128개로 하지만, 실제 sequence의 length는 R을 넘는 경우가 많음. 실제 length가 R을 넘는 경우에도 최신 정보에 해당하는 R개의 token만 residual cache에 보관되며, 나머지는 quantization됨.
이런 방식으로 residual cache를 제한하기 때문에 전체 메모리에서 residual cache가 차지하는 비중은 매우 미미하기 때문에 overhead가 조금 생김에도 불구하고 매우 큰 메모리 절감효과를 얻을 수 있음. 또한, 긴 문맥에서 메모리 효율성이 극대화될 수 있음.
Sliding window의 경우 key cache의 경우 $R^{2}$의 크기를 가지며, value cache의 경우 $R$의 크기를 가짐.
이러한 sliding window 구조를 통해 데이터를 $R$개까지 residual cache에 저장하고, $R$이 넘는 경우 quantized 되어 grouped cache로 이동됨.
Experiments

실험은 대화형 질문응답 지표인 CoQA, 사실을 근거로 얼마나 신뢰성 있는 답을 하는지 평가하는 TruthfulQA, 초등학생 수준의 수학문제 풀이능력을 의미하는 GSM8K task로 진행하였음.
위 테이블에서 볼 수 있듯, 2bit quantization에서 가장 성능을 KIVI가 보였으며, GSM8K에서는 2%의 성능하락밖에 일어나지 않았음.

메모리 사용량과 throughput(일정시간 기준으로 처리할 수 있는 작업의 수)에서도 base-line보다 KIVI가 모두 우수한 성능을 보임.
특히, memory usage그래프에서 32의 residual length (파란선)의 경우 KIVI를 활용했을 때 base-line보다 메모리 사용량을 매우 큰 폭으로 절감시켰으며, 줄어든 메모리 사용량으로 인해 400 batch-size까지 학습이 가능함을 보여줌.
Throughput 그래프에서도 KIVI의 경우 batch-size 증가에 따라 throughput이 좋은 성능을 보이는 것을 확인할 수 있음.
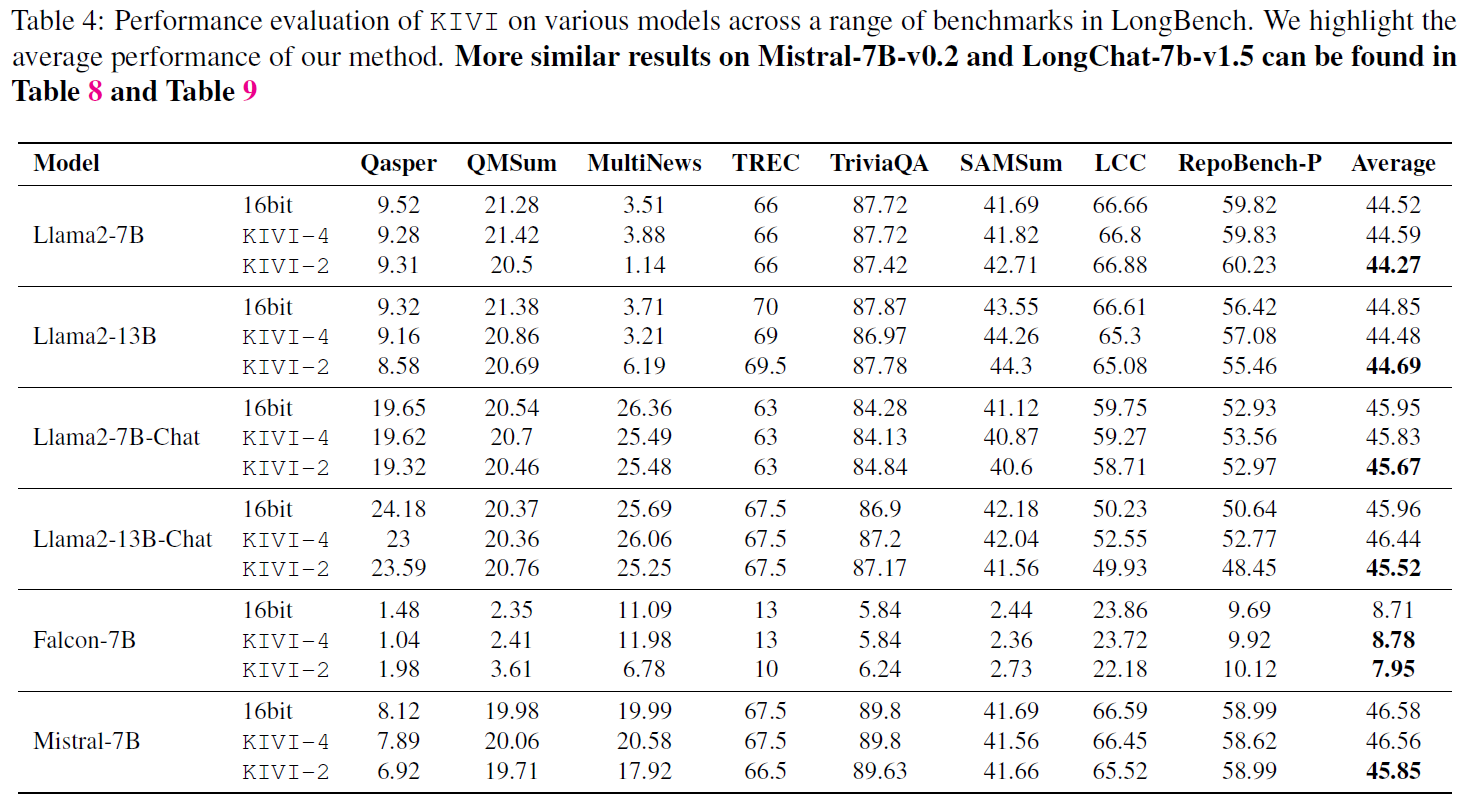
다양한 모델에서 long bench(아래의 벤치마크 셋) 검증 결과, 2bit 환경에서도 KIVI는 16-bit model과 비교했을 때 대부분의 benchmark에서 좋은 성능을 보임.
Qasper: 질문응답
QMSum: 회의내용 요약
MultiNews: 뉴스기사 요약
TREC: 질문응답 (정보검색 위주)
TriviaQA: 질문응답 (퀴즈형식)
SAMSum: 대화요약
LCC: 긴 문맥이해
RepoBench-P: 질문응답 (프로그램 및 소프트웨어 관련)
추가적으로, 본 논문에서는 group size와 Residual length에 대한 ablation study도 진행하였음.

이 결과를 통해, 저자들은 group size는 고려할만한 패턴이 없다는 사실을 분석하였으며, residual length의 경우 length가 클수록 더 좋은 성능을 보이는 경향이 있음을 분석하였음. 따라서, 큰 residual length를 고려하는 것이 중요하다고 강조함.
Conclusion
본 논문에서는 LLM에서 KV cache의 요소를 체계적으로 분석하였음. 그 결과, Key cache의 경우 channel별로 quantization 해야 하며, Value cache는 token별로 quantization 해야 한다는 결론을 도출함. 이러한 결론을 바탕으로 별도의 tuning 없이 바로 적용이 가능한 2-bit KV cache quantization algorithm인 KIVI를 제안함. KIVI는 최대 4배 더 큰 batch-size와 3.47배의 throughput을 허용함. 향후 연구로는 pre-fill 및 decoding 단계에서 quantizatnion overhead를 줄이기 위한 최적화 연구를 진행할 예정임.
Review (Weakness)
1) 논문에서는 긴 context에도 메모리 효율성이 극대화 될 수 있다고 주장함. 하지만, residual cache의 크기를 일정크기로 제한하면서도 어떤 이유로 긴 context를 처리될 수 있는건지 상세하게 분석하지 않음.
2) Real-time application의 활용을 위한 검증이 미흡함. 특히, 긴 context를 처리하는 모델은 latency가 중요한 평가지표이지만 해당 검증이 부재함. 다양한 GPU환경과 메모리 제약조건을 설정한 후 efficiency에 대한 분석을 진행하면 모델 범용성에 대한 강점을 더욱 부각시킬수 있을 것 같음.



