Chen, Defang, et al. "Cross-layer distillation with semantic calibration." Proceedings of the AAAI conference on artificial intelligence. Vol. 35. No. 8. 2021. (AAAI 21)
https://ojs.aaai.org/index.php/AAAI/article/view/16865
Abstract
Feature map을 기반으로 지식을 전이하는 기존 feature distillation은 student model을 효과적으로 training시키는 방식임. 하지만, 의미론적 정보(semantic information)는 다양한 layer에 분포하며 이는 부정적인 regualrization을 유도함. 이러한 현상은 teacher모델과 student model간 layer에서 semantic mismatch를 유발함.
본 논문에서는 이러한 한계를 해결하기 위해 "Semantic Calibration for Cross-layer Knowledg Distillation" (SemCKD)를 제안함.
SemCKD는 각각의 student layer에서 가장 적절한 teacher layer를 attention distribution을 기반으로 자동 선별함.
이러한 방식을 통해 하나의 layer를 고정하여 지식을 전이받는 기존 방식과 달리, 여러개의 cross-layer supervision을 갖음.
SemCKD를 활용한 method는 teacher model과 student model 구조를 갖는 다양한 모델들에 비해 월등한 성능향상 효과를 보이며 STOA성능을 달성함.
Introduction
Knowledge Distillation에서 최대한의 성능향상을 위해 Feature map과 layer 간 연관성을 보장하는 것은 매우 도전적인 과제임. 하지만, 기존의 연구는 feature map이 효과적인 정보를 전달하기 위한 방식으로 사람이 일일히 지정(hand-craft)하는 데 집중되어 있음. (ex) 랜덤 layer 선정, 1대1 layer 선정
하지만, 이러한 직관적인 접근은 teacher-student layer 간 mismatch를 유발할 수 있음.
따라서 본 논문에서는 보다 효율적이고 flexible하게 feature map을 지식전이하는 접근을 하며, Semantic Calibation for Cross-layer Knowledge Distillation (SemCKD)를 제안함.
SemCKD를 통해 모델의 중간 지식을 활용할 수 있으며, 이를 통해 sementic level을 match시킴.
sotf layer asssociation을 자동화하기 위해 attention mechanism을 활용함.
논문의 핵심 contributions는 다음과 같음.
1. Semantic calibation via soft layer assiciation 기반의 새로운 접근을 통해 feature map의 지식전이능력을 향상시킴.
2. Cross-layer distillation을 위한 soft layer association을 위해 attention mechanism을 활용함.
3. CIFAR-100 및 ImageNet 실험결과 SemCKD는 전반적으로 향상된 성능을 보이며 SOTA를 달성함.
Related Work
Knowledge Distillation, 특히 feature distillation에 활용되는 일반적인 loss function은 다음과 같음.

여기서 $L_{KD}$는 logit distillation을 의미하며, $L_{FMD}$는 feature distillaiton을 의미함. Knowledge distillation은 logit distillation loss를 통해 input에 대한 loss를 산출함.

$L_{CE}$는 label과의 지도학습에 해당하며, $L_{KL}$은 teacher model의 output $\sigma(g_{i}^t/T)$과 student model의 output $\sigma(g_{i}^s/T)$간 kullback-leibler divergence loss를 의미함. T는 temperature로 teacher model의 output값을 smoothing하는 역할을 함.
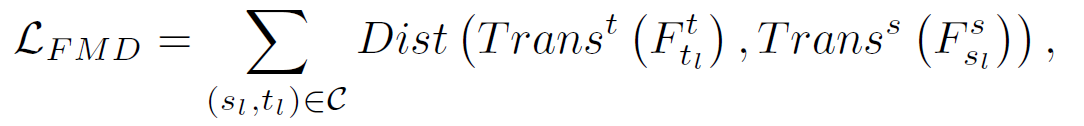
feature distillation은 teacher model의 직접적인 모델정보를 전이시키기 위해 layer의 feature map을 기반으로 한 distillation loss를 연산함. 수식의 Trans는 tranform된 feature map을 의미함. $F_{t_{l}}^{t}$는 teacher layer의 feature map을 의미하며, $F_{s_{l}}^{s}$는 student layer의 feature map을 의미함. 이 두 feature map 간 distance를 기반으로 feature distillation loss를 계산할 수 있음.
이어서 본 논문에서는 feature distillation에 해당하는 $L_{FMD}$를 $L_{SemCKD}$로 새롭게 제안함.
Method

본 논문에서는 각각의 student layer에 적합한 teacher layer을 찾기 위해 2가지 과정을 거침.
1) Semantic Calibration
2) Attention Allocation
1) Semantic Calibration
Student layer의 각 feature map은 다양한 teacher layer와 동일한 크기를 갖지않음. 하지만, student-teacher간 pairwise similarity를 연산하기 위해서는 동일한 크기로 맞춰야함.
이를 위해 student layer의 feature map은 Overall Method의 왼쪽그림과 같이 feature map projection 과정을 통해 동일한 크기로 맞춤.
위 과정을 거친 후 아래와 같은 loss를 제안하며, 하나의 student layer가 모든 teacher layer를 고려하는 loss를 연산함.

여기서 Dist는 기존의 feature distillation loss와 같이 두 feature map 간의 distance를 계산하는 함수이며, 논문의 저자들은 거리계산을 위해 MSE loss를 활용함.
수식에서 $F_{t_{l}}^{t}$는 teacher layer의 feature map을 의미하며, Proj( $F_{s_{l}}^{s}$, t_{l})은 위에서 언급한 projection 과정을 마친 student layer의 feature map을 의미함. 이 두 featuremap을 통해 distance 계산을 진행하며, $\alpha_{s_{l},t_{l}}$는 attention mechanism을 통해 계산한 similarity를 의미함.
(여기서 의미하는 similarity는 feature map의 중요도를 의미)
$b$는 미니배치의 사이즈를 의미함 (미니배치 내 데이터셋 수)
2) Attention Allocation
attention mechanism은 student layer에 가장 적합한 teacher layer를 선정하기 위해 연산됨.

attention 연산은 위 그림과 같이 이루어짐.
student layer의 feature map은 query로 들어가며, 각 teacher layer의 feature map은 key에 해당함.
이러한 input을 통해 dot product attention을 수행함으로써 query에 해당하는 student feature map은 모든 teacher feature map들과의 pairwise similarity를 계산할 수있음. 각각의 계산된 similarity 값은 softmax함수를 거쳐 저장됨.
해당 수식은 아래와 같음.

Query에 해당하는 $Q$는 transpose되며, Key에 해당하는 $K$와의 dot-product (내적)을 통해 similarity를 구할 수 있음.
추가적으로 softmax과정을 거쳐 최종적인 $\alpha$ 가중치를 얻을 수 있음. 여기서 $i$는 미니배치 내 하나의 데이터를 의미함.
예를 들어 $Q$가 1x4 형태이고, $K$가 1x4형태인 경우 transpose된 $Q$는 4x1형태가 됨.
따라서, $Q^{T}$와 $K$를 내적하면 4x4형태의 similarity matrix가 생성됨.
이는 $i$번째 데이터의 matrix가 될 수 있으며, 미니배치 내 $b$개의 전체 데이터만큼의 4x4 matrix가 추가적으로 구성됨
이와 같은 연산을 통해 가중치 $\alpha$를 계산할 수 있으며, student feature map은 모든 teacher feature map을 가중치 (similarity 값)에 따라 loss를 도출함. (Propose Loss function 참고)
따라서, 좋은 similarity값을 갖는 layer는 큰 $\alpha$값을 가져 큰 비중으로 학습되며 좋지 않은 similarity를 갖는 layer는 작은 비중으로 학습됨.
Experiment

제안하는 SemCKD는 CIFAR-100 데이터셋에서 기존의 knowledge distillation method에 비해 탁월한 성능을 보임.

ImageNet의 경우에도 제안 method가 우수한 성능을 보임.


Figure 2는 teacher $ student model의 조합을 다르게 하여 임의적으로 distillation하는 경우 negative regularization효과가 극대화 됨을 나타냄. 결과적으로 잘못된 layer matching은 기본적인 KD보다 성능이 나빠질 수 있음을 시각화하여 보여줌.
Table 3의 경우 Semantic Mismatch score를 구했으며, 제안방식이 가장 낮은 점수를 얻음으로써 mismatch가 가장 덜 일어났음을 분석하였음.
Grad-CAM을 통해서도 SemCKD가 가장 prediction을 적절히 했음을 시각적으로 확인할 수 있음.
Conclusion
본 논문은 여러 layer에 포함된 지식을 자동으로 선정하기 위해 attention distribution을 활용하였으며, 이를 통한 calibration과정을 제안함. 이를 통해 여러 중간 계층의 feature map들은 distillation성능을 향상시키는데 효과적임.
실험결과에 따르면, SemCKD는 상대적으로 낮은 수준의 semantic mismatch score를 보이며, 기존의 접근방식보다 뛰어난 일반화 성능을 보임.



